





- 1 典型F5 BIG-IP LTM负载均衡器部署方式采用“双臂旁挂”式连接“双机热备”
- 2 《Android平板电脑开发秘籍》——3.2节技巧:显示或隐藏ActionBar
- 3 ldd命令,查看依赖的动态库信息 nm命令可以列出一个函数库文件中的符号表
- 4 数据库基础复习以及一些面试题
- 5 crontab巨坑问题
- 6 sass进阶—mixin的使用(浏览器兼容性调整)
- 7 java导入多个sheet_java导入excel,多sheet
- 8 python解释器的工作原理_编程的分类,以及运行python解释器的原理,最后变量
- 9 [css] box-shadow层级问题-相邻元素背景遮盖了阴影
- 10 Prometheus监控实战系列九:主机监控
记录一个在工作中遇到的一个场景:数据规则是根据某个字段作为唯一标识存储数据,但是在业务使用中发现有重复数据,需要把这些数据筛查出来。下面分别以MySQL和MongoDB来举例说明:MySQL根据user表中的code字段查找重复数据
select code,count(*) from user group by code having count(*) > 1;db.getCollection('user').aggregate([ { $group: { _id : '$code', count: { $sum : 1 } } }, { $match: { count: { $gt : 1} } }])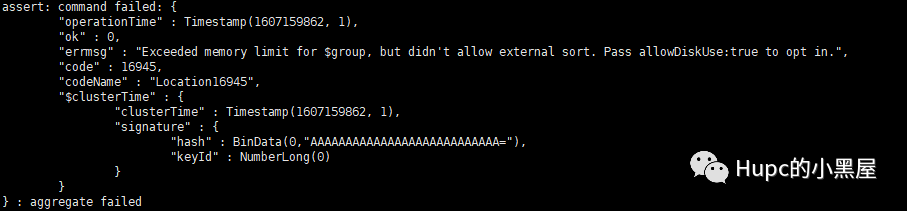
db.getCollection('user').aggregate([ { $group: { _id : '$code', count: { $sum : 1 } } }, { $match: { count: { $gt : 1} } }],{allowDiskUse:true})the end~