什么是网络爬虫?
网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。所以要想抓取网络上的数据,不仅需要爬虫程序还需要一个可以接受”爬虫“发回的数据并进行处理过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求则越高。
网络爬虫的实现原理
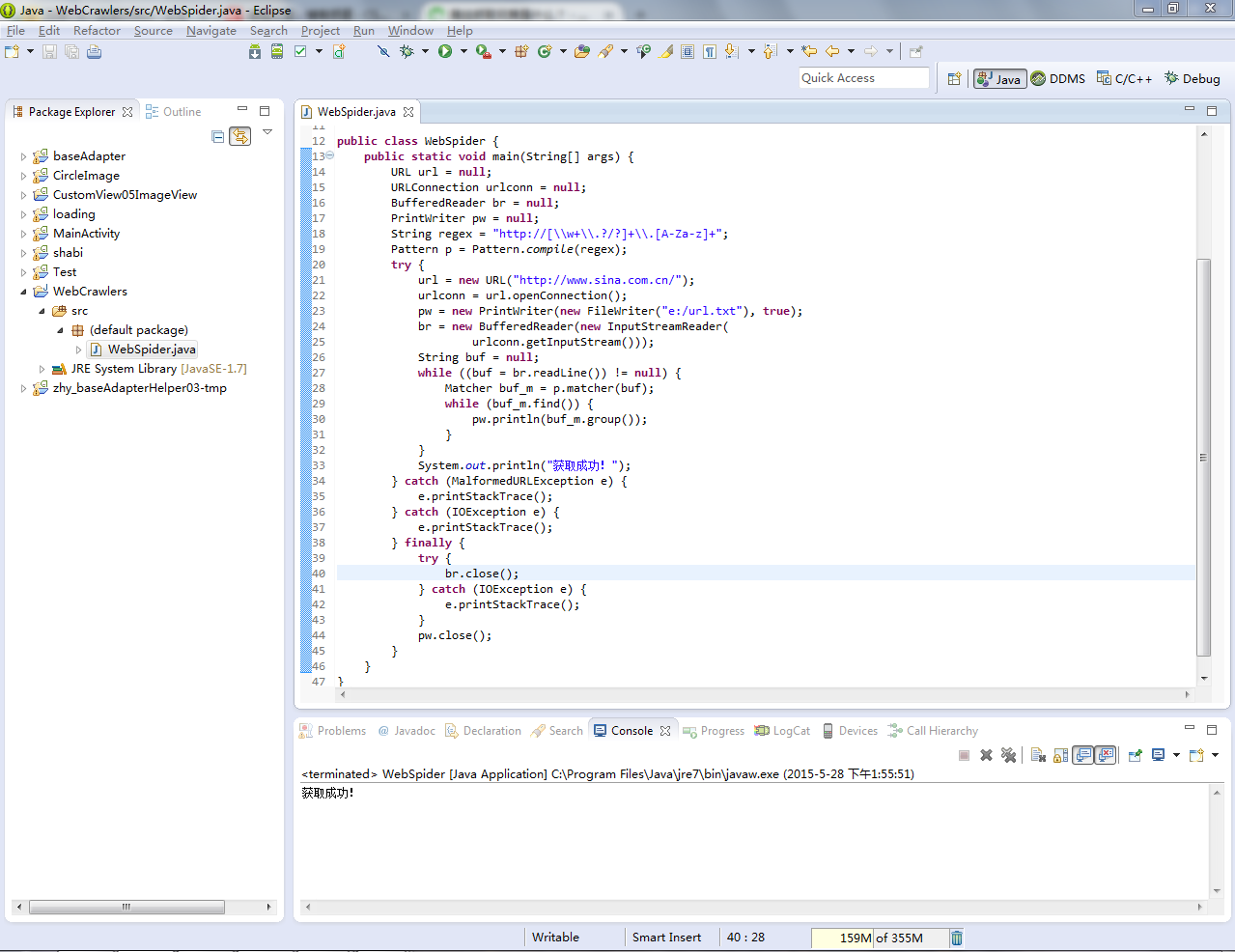
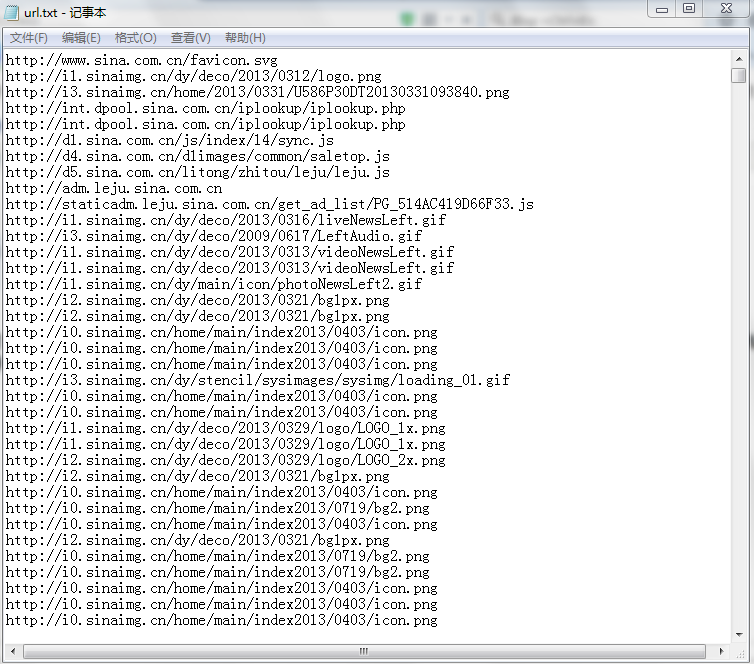
根据这种原理,写一个简单的网络爬虫程序 ,该程序实现的功能是获取网站发回的数据,并提取之中的网址,获取的网址我们存放在一个文件夹中,关于如何就从网站获取的网址进一步循环下去获取数据并提取其中其他数据这里就不在写了,只是模拟最简单的一个原理则可以,实际的网站爬虫远比这里复杂多,深入讨论就太多了。除了提取网址,我们还可以提取其他各种我们想要的信息,只要修改过滤数据的表达式则可以。以下是利用Java模拟的一个程序,提取新浪页面上的链接,存放在一个文件里
源代码
- import java.io.BufferedReader;
- import java.io.FileWriter;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.io.PrintWriter;
- import java.net.MalformedURLException;
- import java.net.URL;
- import java.net.URLConnection;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class WebSpider {
- public static void main(String[] args) {
- URL url = null;
- URLConnection urlconn = null;
- BufferedReader br = null;
- PrintWriter pw = null;
- String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
- Pattern p = Pattern.compile(regex);
- try {
- url = new URL("http://www.sina.com.cn/");
- urlconn = url.openConnection();
- pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
- br = new BufferedReader(new InputStreamReader(
- urlconn.getInputStream()));
- String buf = null;
- while ((buf = br.readLine()) != null) {
- Matcher buf_m = p.matcher(buf);
- while (buf_m.find()) {
- pw.println(buf_m.group());
- }
- }
- System.out.println("获取成功!");
- } catch (MalformedURLException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- try {
- br.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- pw.close();
- }
- }
- }